Stop gluing Jira onto your sdlc and calling it transformation
We are currently in the “Trough of Disillusionment” for AI development tools.
Walk into any modern engineering organisation, and you will see “AI” everywhere. There is a sparkle icon in the IDE, a “Summarise” button in Slack, and a “Generate Description” feature in Jira. The PR Review Agent catches bugs. Management look at this and see a revolution. Engineers look at this and see noise.
The evidence is mounting that these tools aren’t yet delivering the promised velocity. Stack Overflow’s 2025 survey shows that while 84% of developers use AI tools, only 33% trust the output. 46% distrust the output.
None of this is actually bad. For many teams, these assistants are a genuine upgrade on the old world. But when you look at the actual outcomes that matter for a product development business - lead time, customer-impacting incidents, backlog quality - most organisations are not seeing a step change.
What “AI in the SDLC” Usually Means Today
We don’t have a global census of internal dev tools, but if you look at how vendors position themselves, how platform engineering teams talk about their roadmaps, and what shows up in public case studies. A familiar pattern emerges.
For most teams, “AI in the SDLC” looks roughly like this (Atlassian toolchain only):

Atlassian AI Tools chain
There’s nothing inherently wrong with this. In fact, it’s exactly what you’d expect from early adoption: local optimisations around existing workflows.
The problem is what usually doesn’t exist:
- No deliberate context fabric:
- Jira issues are inconsistent.
- Links between Jira, Git, incidents and Confluence are optional and patchy.
- Slack is full of decisions that never make it into durable artefacts.
- CI/CD doesn’t know or care whether behaviours are AI-driven or not.
- No explicit AI-aware SDLC:
- No clear phase where AI behaviours are designed, evaluated and hardened.
- No standard for how AI work moves from prototype → test → rollout → monitoring.
So you end up with this weird split:
- Locally, people feel productivity gains (“this plugin is handy”).
- Systemically, nothing in your SDLC has actually been redesigned to take advantage of AI.
You’ve only added intelligence at the edges. You haven’t changed the operating model.
How do we know we are failing?
Why do most current AI tools fail to deliver real velocity? We can explain it with one of the most fundamental rules of software engineering: The Liskov Substitution Principle (LSP).
In code, LSP states that objects of a superclass shall be replaceable with objects of its subclasses without breaking the application.
In an org chart, the same rule applies. If you replace a human step (e.g., “Junior Dev Reviews PR”) with a synthetic step (e.g., “Agent Reviews PR”), the process should hold.
Currently, it breaks.
- The Human Junior: Reads the ticket, checks the Slack thread for the real context, checks the architectural decision record (ADR), and then reviews the code.
- The AI Tool: Sees only the diff. It ignores the Slack conversation (because it can’t see it) and the Jira requirements (because it isn’t connected).
The Agent generates a review that is syntactically correct but architecturally wrong. The Senior Engineer then spends more time validating the AI’s review than if they had done it themselves. The substitute has failed.
The Architecture: Gluing vs. Native
The difference between a toy and a tool is how it integrates with your system. We are currently seeing two distinct patterns emerge in engineering teams:
1. The “Glued” Model (The Sidecar) This is what most teams have today. The AI is a chatbot that sits alongside the work.
- Trigger: Pull. The human must manually ask, “Explain this code.”
- Context: Keyhole. The model sees only the file you have open.
- Output: Chat. It gives advice (“You should change this variable”).
- Result: Individual Productivity. One engineer might type faster, but the system remains unchanged.
2. The AI-Native Model (The Infrastructure) This is what elite teams are building. The AI is a component inside the pipeline.
- Trigger: Push. The AI listens for webhooks (
git push,pagerduty.alert). It runs automatically. - Context: Graph. The model queries a Knowledge Graph of Jira tickets, Slack threads, and Git history.
- Output: State Change. It performs work (e.g., posting a structured review comment to the PR API).
- Result: Systemic Velocity. The entire fleet moves faster because the baseline quality is enforced automatically.
The Framework: The Synthetic SDLC
To move from “Decoration” to “Transformation,” I propose a maturity model for your platform: **The Synthetic SDLC.
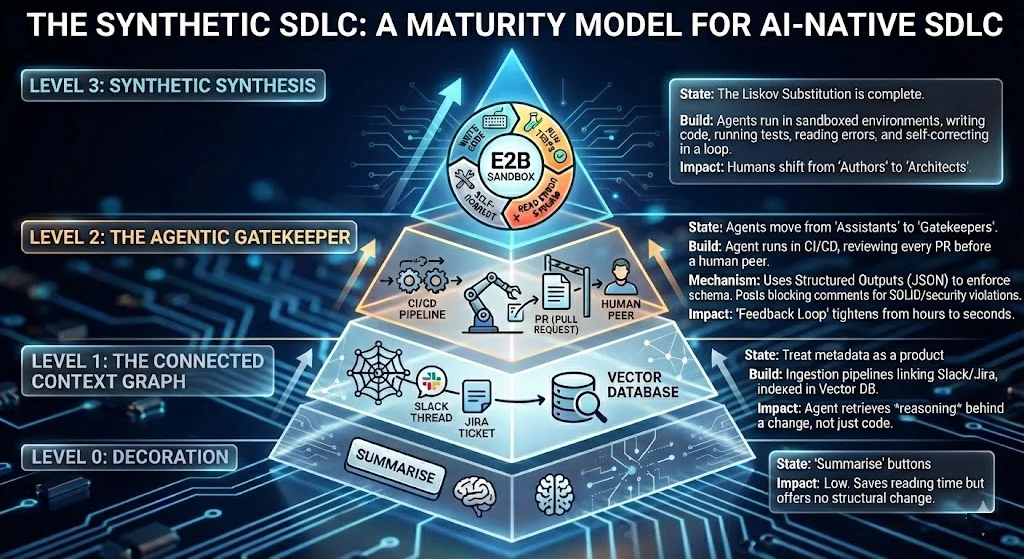
Maturity Model for an AI-Native SDLC
Level 0: Decoration
- State: “Summarise” buttons.
- Impact: Low. It saves reading time but offers no structural change.
Level 1: The Connected Context Graph
- State: You treat your metadata as a product.
- The Build: You build ingestion pipelines that link Slack threads to Jira tickets and index them in a Vector Database.
- Impact: When an Agent runs, it retrieves the reasoning behind a change, not just the code.
Level 2: The Agentic Gatekeeper
- State: Agents move from “Assistants” to “Gatekeepers.”
- The Build: An Agent runs in your CI/CD pipeline (e.g., GitHub Actions). It reviews every PR before a human peer does.
- The Mechanism: It doesn’t just “chat.” It uses Structured Outputs (JSON) to enforce a schema. It posts blocking comments if code violates SOLID principles or security standards.
- Impact: The “Feedback Loop” tightens from hours to seconds.
Level 3: Synthetic Synthesis
- State: The Liskov Substitution is complete.
- The Build: Agents run in sandboxed environments (like E2B) where they can write code, run tests, read the error stream, and self-correct in a loop.
- Impact: Humans shift from “Authors” to “Architects.”
The Takeaway
We need to stop gluing models to Jira and calling it innovation.
Real transformation happens when we build a Context Layer that allows an Agent to understand why a feature exists, and an Execution Layer that allows it to enforce standards automatically.
Once you connect the silos and automate the gatekeeping, you don’t just get a faster Jira; you get the foundation for an AI-Native engineering team.