How to Stop Wasting Time on the Wrong Kind of “AI”
Everywhere I look right now, teams are “doing agents”. You know the pattern. Someone senior announces that the organisation needs an “AI story”, a squad spins up, a vendor demo lands well, and suddenly there’s a big agent-shaped item on the roadmap.
Thank you Atlassian!
As a manager, I see teams rushing to build complex “agentic” chains just to parse CSV files, or scrape static websites, or move data from Table A to Table B. They treat the LLM as a “Golden Hammer” - a magical tool that can fix any data problem.
Fast-forward a quarter and you have:
- A fragile “agent” orchestrating half a dozen systems.
- A mess of prompt logic nobody really wants to touch.
- A demo that works on good days.
- A maintenance bill that looks suspiciously like a long-term tax.
This is all part of a dangerous trend right now: the urge to use LLMs to solve deterministic problems.
While it’s true that an Agent can do these things, that doesn’t mean it should.
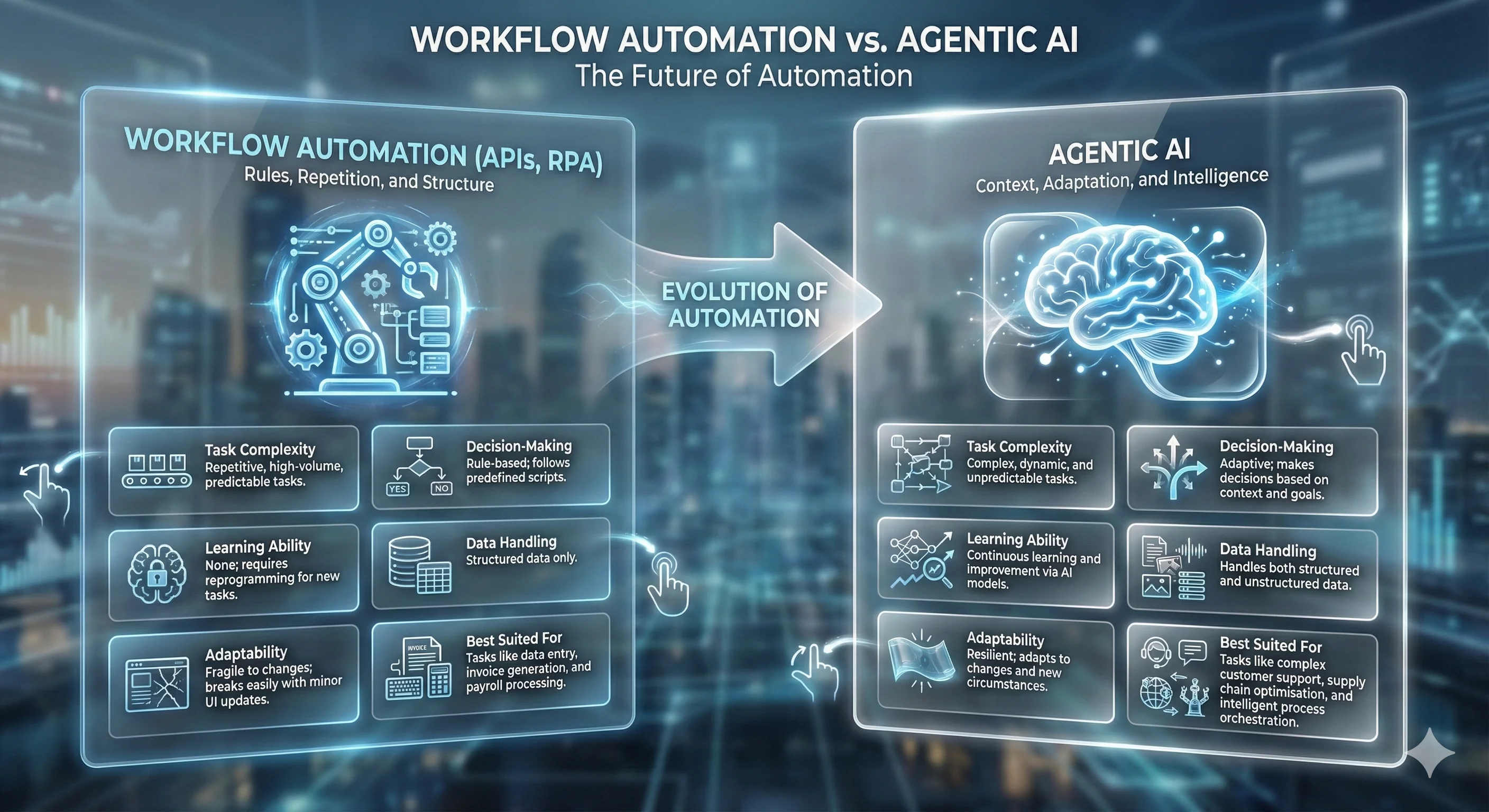
Different approaches to operations optimisation
When you use a probabilistic model (AI) for a deterministic task, you are voluntarily paying a “Reliability Tax”. You are introducing latency, exploding your token costs, and -worst of all - introducing the risk of hallucination into a process that should be 100% predictable. Sadly, the outcome is often one of:
- You’re using a $10M foundation model to parse a CSV file.
- You’re also using a brittle, 200-line Python script to handle sensitive customer complaints.
The friction is palpable: soaring cloud bills from over-engineered agents, and operational fires caused by under-engineered scripts. Teams are left disillusioned and leaders start to question whether AI is just another bubble.
At portfolio level, execs can’t get a straight answer to a basic question:
“For this task, should we be using agents, automation, a script, or a human in the loop?”
A Simple Way to Decide: The Ambiguity Matrix
The difference between a successful AI initiative and a costly failure often isn’t the model you choose, data quality, or MVP purgatory. It’s simply knowing when not to use AI at all. So, let ’s stop arguing from vendor decks and put a tiny bit of structure around this.
 The Automation Ambiguity Matrix
The Automation Ambiguity Matrix
To solve this, I propose a decision framework for your engineering teams: The Automation Ambiguity Matrix.
We map the problem on two axes:
- Ambiguity of Input/output (How structured is the data? Inputs are natural language, context-heavy or fuzzy; outputs involve judgement or trade) and
- Impact of Error (‘Just Annoying’ to ‘Severe Financial Impact’).
-
Low Ambiguity / Low Impact of Error: Write a Script. (e.g. moving files, simple ETL). Don’t over-engineer.
-
Low Ambiguity / High Impact of Error: Use Automation, Classic Workflow Engines, RPA (e.g. processing standard invoices, legacy system data entry).
-
High Ambiguity / Low Impact of Error: Use a Single LLM Call. (e.g. summarising an email, sentiment analysis).
-
High Ambiguity / High Impact of Error: Build an Agentic System. (e.g. customer support with refund authority, researching market trends).
The Golden Rule: Only move to the right (towards AI) when the ambiguity demands it.
Business Impact (ROI)
Adopting this matrix drives immediate ROI:
Portfolio Clarity:
- Fewer doomed agent projects.
- Faster time-to-value as teams pick the right approach first time.
A clear Portfolio Narrative:
- “We use automation, API scripts and RPA where the world is predictable.”
- “We use agents where the world is fuzzy but the risk is containable.”
- “We keep humans in the loop where both fuzziness and risk are high.”
- You can show your roadmap segmented by solution class and quadrant, not just by “AI vs non-AI”.
Cost:
- Agents reserved for where they add unique value, not as default.
- Lower infra and maintenance costs on low-ambiguity work.
Speed:
- Low-ambiguity, low-risk tasks get done with scripts and workflows
- Classic scripts run in milliseconds; Agents run in seconds.
Better risk/engineering alignment:
Risk, compliance, and security teams get a simpler view:
- Certain quadrants (e.g. high-risk) trigger mandatory review patterns.
- Others (low-risk) can use a lighter-weight approval.
The Takeaway
Innovation doesn’t mean reaching for the latest gadget for everything. Innovation means using the right tool for the job. Nail that distinction, and everything else you care about - the SDLC, context engineering, DevEx, ROI - becomes much easier to manage. Get it wrong, and you’ll keep building very clever solutions to the wrong class of problems.
Next Steps
When considering how to implement such a matrix in practice, bear in mind the following:
- This matrix should show up in your platform as different lanes/golden paths, not just a slide in a deck. To help with this, I will be providing specific examples of ROI in the near future.
- In terms of governance, and in practice, each quadrant maps to a different level of control surface and testing effort.
- There is also great potential for tying in the Automation Ambiguity Matrix into a Talent & Capability matrix.